Managing an IoT Fleet with GitOps
In a previous blog post I showed that it is surprisingly easy to manage an individual IoT device. In another post I described how my OS images get built, dispatched and tested in a fully automatic manner. Based on my initial - rather theoretical - post about the same subject, I will now present how you can manage an entire IoT fleet with a git repository instead of an expensive point and click tool.
The Sample Fleet
To better illustrate the approach, I prepared the following sample fleet:

The fleet is composed of various device types that shall satisfy different use cases:
- ① is a Raspberry Pi 2 that plays the ungrateful role of a legacy device that still needs to be maintained.
- ② is a Compulab IOT-GATE-iMX8 that will be turned into a decent WiFi 6 hotspot once its owner finds some spare time.
- ③ and ④ are Raspberry Pi 3 devices that are configured as kiosk terminals showing a web page.
- ⑤ is a Variscite VAR-SOM-MX8M-NANO module sitting on a Symphony board. It looks like an early prototype of a future product.
- ⑥ and ⑦ are Raspberry Pi 4 devices. One of them acts as a self-hosted GitHub actions runner while the other one is yet another kiosk terminal.
For the devices we expect different levels of availability depending on their use case and exposedness. Let’s imagine the following scenario: The device ⑥ serves as a GitHub actions runner and shall only have minimal downtimes as the development team always wants to be able to build new OS images. Also, the WiFi hotspot (device ②) should be permanently available. The kiosk terminal ③ might be located at the central station (a downtime is embarrassing) while the device ④ is on the own company campus (the employees of the company shall see the terminal, and they are supposed to complain if something does not work as expected). Last but not least we have the Variscite board ⑤ that is being used to develop a new product. Nobody - expect the developer - will notice if this device is offline.
Accordingly, we can group the devices:
- Production group: From the devices ① ②, ③ and ⑥ we expect high availability. The updates on those devices shall only happen if the corresponding software has been thoroughly tested.
- Canary group: ④ is a typical canary device. The new products shall get verified on the company campus first.
- Qualification group: ⑦ might belong to a qualification group that automatically gets the software that the development team wants to release next.
- Dynamic group: The development device ⑤ might be dynamically added to one of the above groups or no group at all.
The Fleet Management Repository
The fleet management repository is designed to be operated with the above fleet setup:
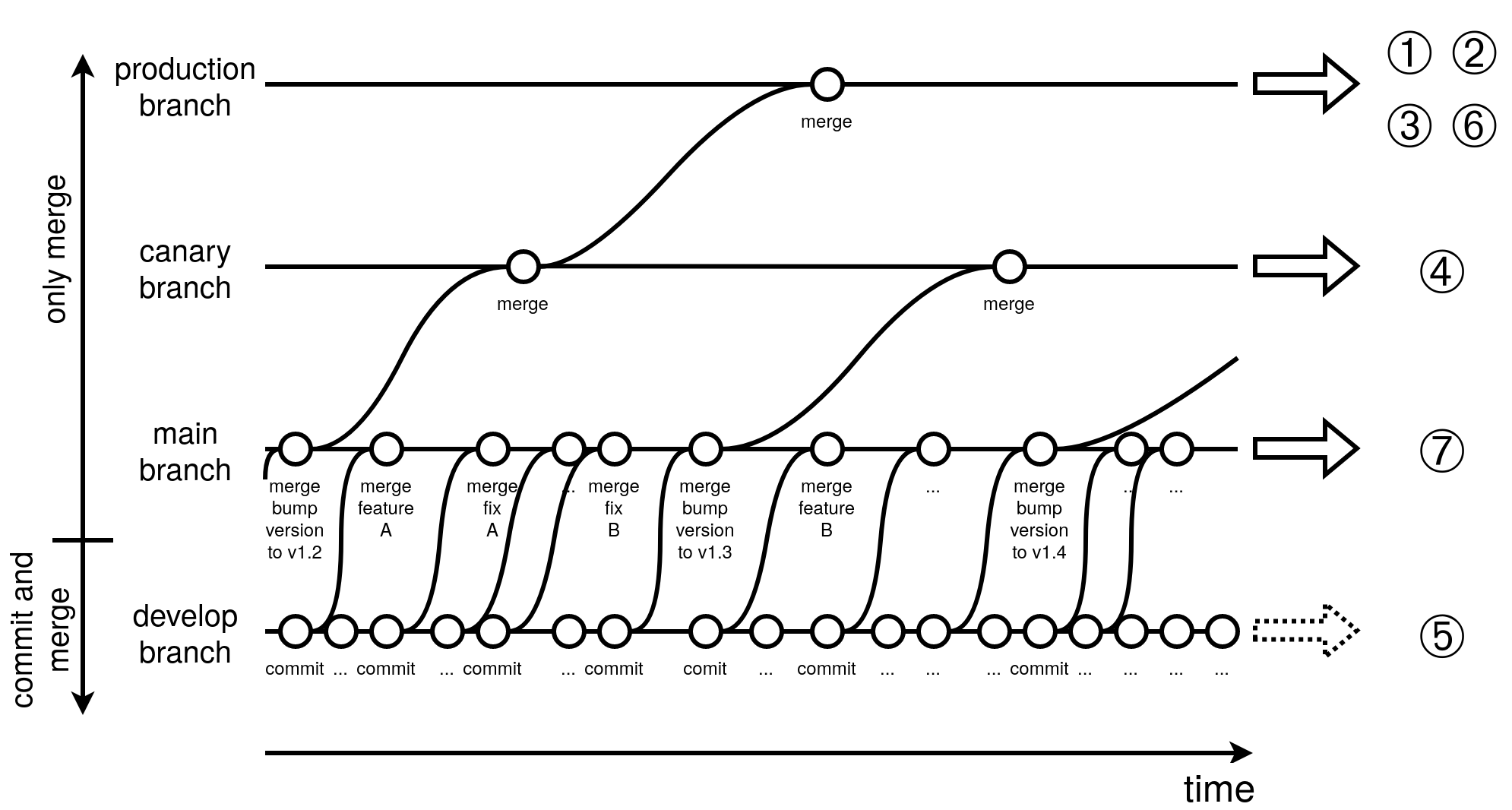
The repository works as follows: On the develop and feature branches (not depicted) the development gets done. On the main branch and beyond only merges are allowed. The canary branch only accepts merge requests from the main branch. The production branch only accepts merge requests from the canary branch. The merging to the canary and the main branch is gated and approval from the developers and the site reliability engineers as well as the passing of the automatic quality gates is required to finally make the merge happen. The setup ensures that the updated fleet setup goes unmodified from main to canary and finally to production. If something e.g. fails on the canary level, then there will be no merge to the production branch. For the above sample fleet this means that if changes get merged to the main branch then the devices subscribed to the main branch will get updated (here ⑦). If the team is happy with the changes then a merge request to the canary branch gets created. As soon as the merge request gets finally merged then the canary devices get updated (here: ④). If the canary device(s) are still ok we are ready for the final merge to production. Once merged, the remaining devices subscribed to the production branch will get updated (① ②, ③ and ⑥). Needless to say, that the changes applied to the fleet are idempotent: if you apply the same modifications again, nothing will be changed on the device.
The Workflow
Let’s take a closer look at the fleet management repository:
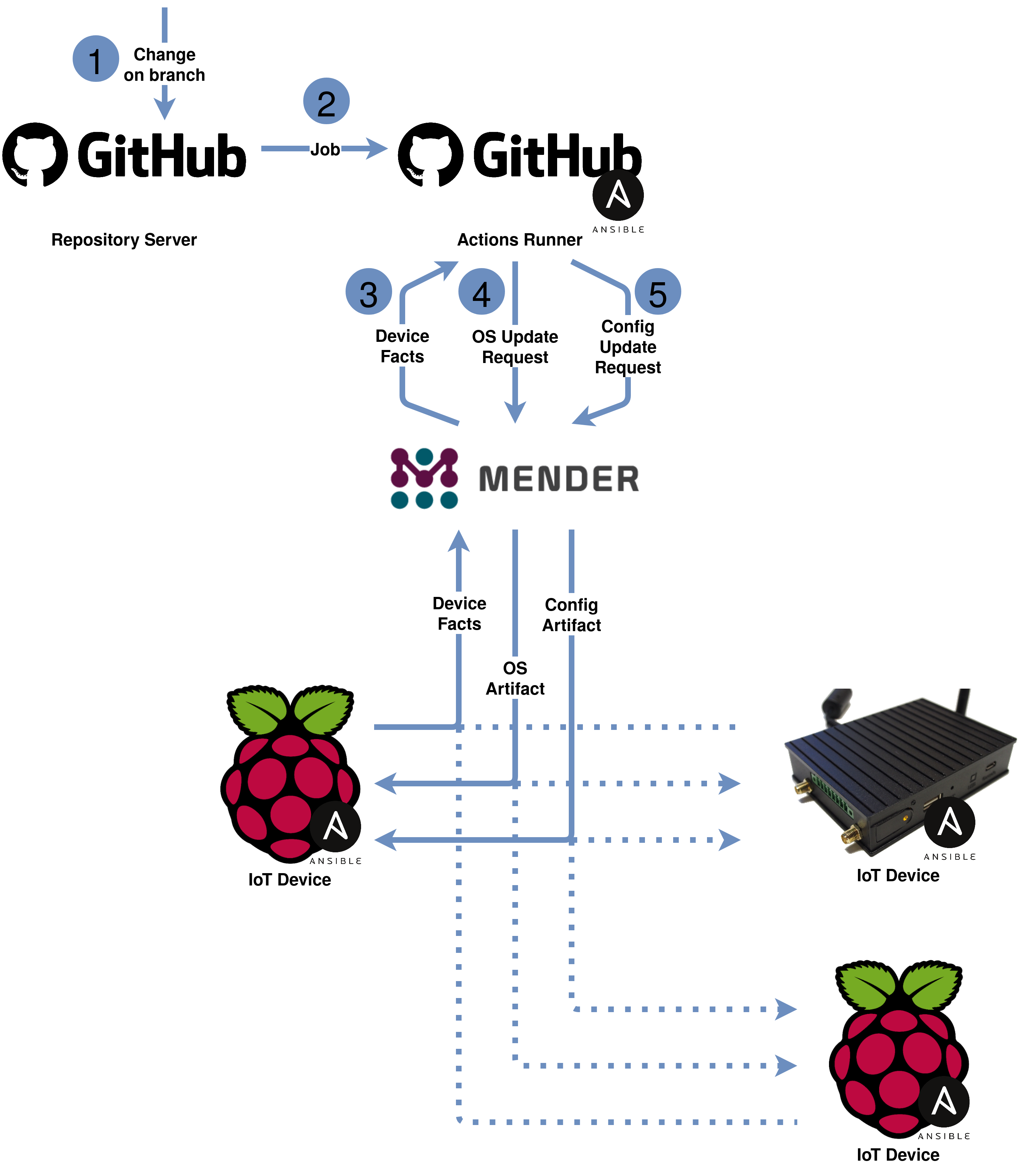
The following components are part of the repository:
- An inventory describing the fleet.
- Individual device configurations.
- An Ansible playbook with three roles.
- A GitHub actions workflow. The job of the workflow is to execute the Ansible playbook.
The playbook is fairly simple but slightly deviates from a standard Ansible playbook. The facts are not gathered from the IoT devices directly but instead are fetched from Mender. Based on the facts gathered and depending on a match between the branch that the device is subscribed to and the branch that is currently being executed the playbook decides if an OS upgrade and/or a configuration update on the device is required. If yes, then the requested changes get initiated via Mender. The playbook does not wait until the changes are fully applied but instead considers its job as completed once the required changes got scheduled on Mender. It is the job of a subsequent monitoring workflow to check the progress of the fleet update.
Scaling the Solution for Large Fleets
For the sake of simplicity the inventory and the device configurations are directly part of the git repository. When dealing with 100k+ devices then managing the inventory and the individual configurations within a git repository will become cumbersome. Therefore, the inventory and the storing of the individual configurations should be offloaded to a dedicated system. Given that this dedicated system has a decent API it is very easy to integrate it into the existing setup. All the rest of the setup is already highly scalable.
Conclusion
Using the above approach you have a seamlessly automated, fully traceable setup that leaves almost no place for human errors. The developers and the site reliability engineers will coordinate their work using the same git repository. The manual steps get reduced to a minimum. The individual components are robust and proven in use. I am sure that the solution presented here will easily outperform many of the IoT platforms currently available.
Outlook: So far we did not touch the monitoring aspect. Preparatory work has already started - maybe this would be a good topic for an upcoming post!
Feedback is highly appreciated - I am sure there is still a lot of room for improvements!
Leave a comment